Czy Twoje AI jest bezpieczne? 10 śmiertelnych zagrożeń dla modeli ML, które mogą zniszczyć Twój biznes w 2025!

W erze eksplozji sztucznej inteligencji, gdy każda firma ściga się o implementację modeli ML, bezpieczeństwo staje się krytycznym elementem, który może zadecydować o sukcesie lub katastrofie. OWASP Machine Learning Security Top 10 to kompleksowy przewodnik po najgroźniejszych zagrożeniach, które mogą dotknąć Twoje systemy AI. Poznaj wrogów, zanim oni poznają Ciebie.
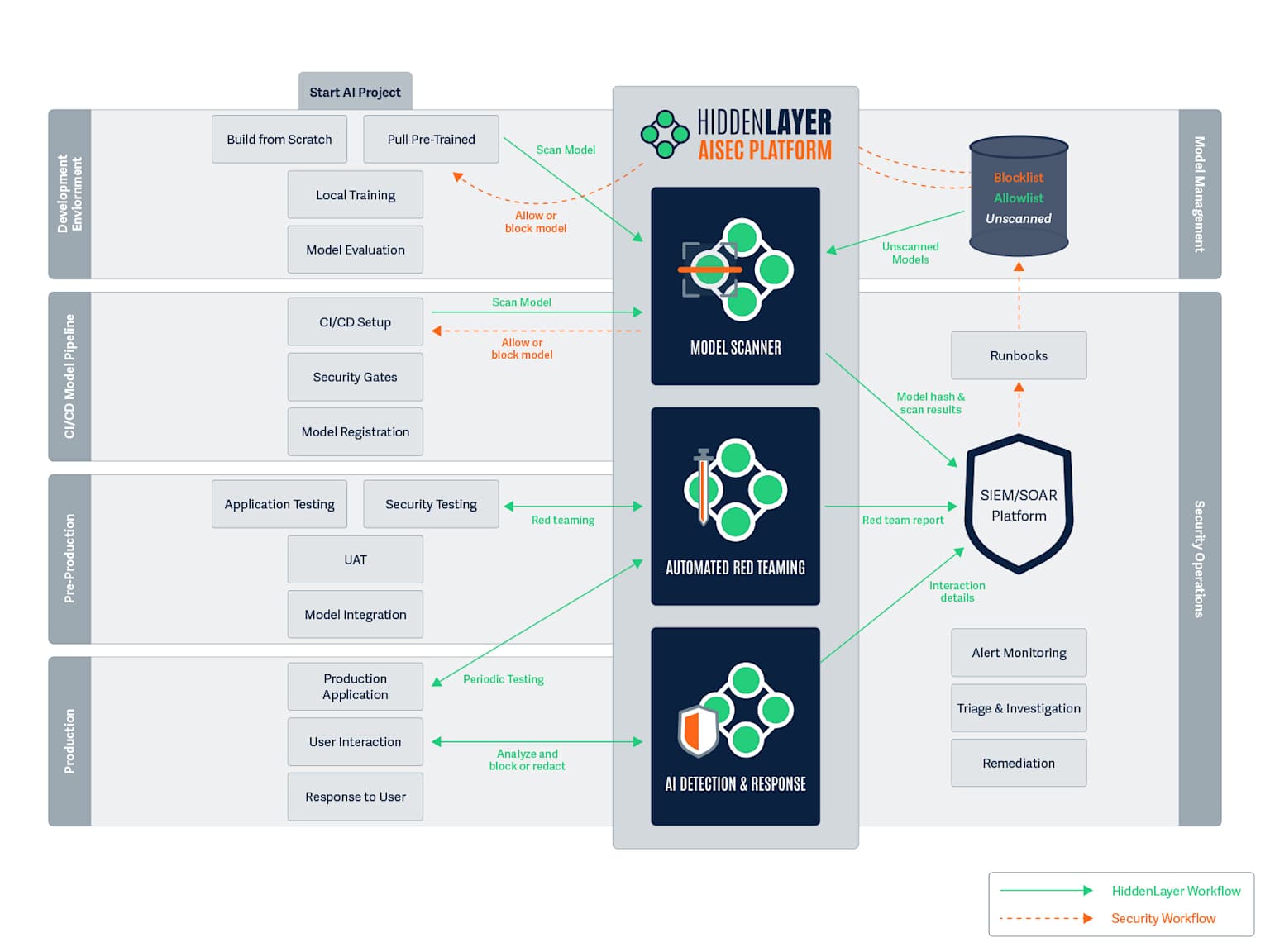
A detailed diagram outlining the integration of security measures across the AI model development and deployment lifecycle.
Dlaczego bezpieczeństwo ML jest kluczowe?
Modele uczenia maszynowego nie są jedynie narzędziami technologicznymi - to strategiczne aktywa biznesowe, które przetwarzają wrażliwe dane, podejmują krytyczne decyzje i mogą być celem wyrafinowanych ataków cybernetycznych. Jedyny błąd w zabezpieczeniach może prowadzić do kradzieży danych, manipulacji wyników, a nawet przejęcia kontroli nad całym systemem.
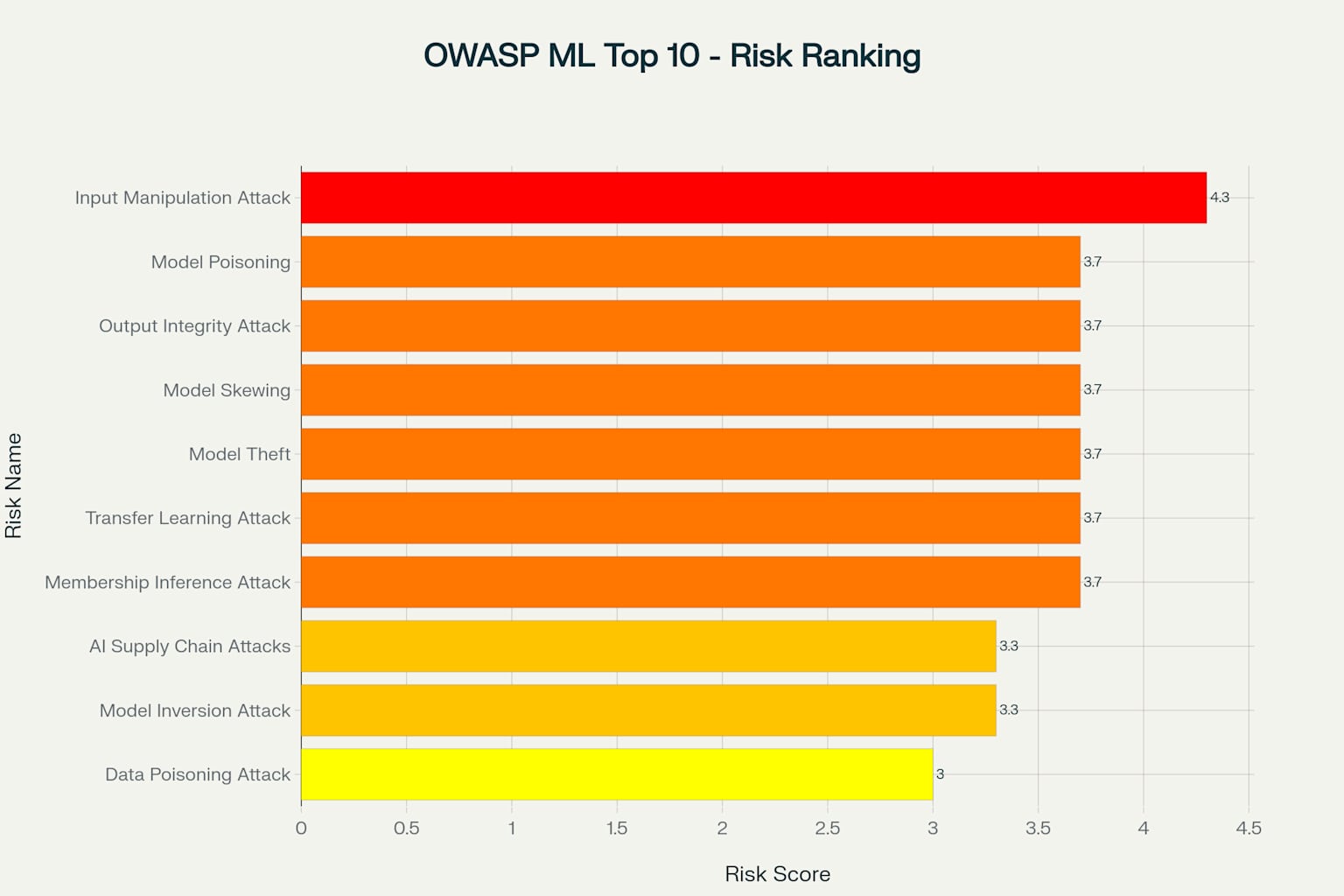
Ranking zagrożeń bezpieczeństwa ML według OWASP - pokazuje 10 głównych ryzyk uporządkowanych według ogólnego poziomu zagrożenia
TOP 10 Zagrożeń Bezpieczeństwa Machine Learning według OWASP
1. ML01:2023 - Input Manipulation Attack (Ataki manipulacji danych wejściowych)
Opis zagrożenia: Napastnicy celowo modyfikują dane wejściowe, aby wprowadzić model w błąd. To najwyżej oceniane zagrożenie w rankingu OWASP12.
Przykład ataku: Dodanie niewidocznych dla oka perturbacji do obrazu kota sprawia, że model klasyfikacji rozpoznaje go jako psa. W systemach bezpieczeństwa może to oznaczać ominięcie systemów rozpoznawania twarzy poprzez dodanie specjalnych naklejek34.
Metody obrony:
- Adversarial Training: Trenowanie modelu na przykładach adversarialnych2
- Input Validation: Walidacja danych wejściowych pod kątem anomalii2
- Robust Models: Wykorzystanie architektur odpornych na manipulacje2
2. ML02:2023 - Data Poisoning Attack (Ataki zatrucia danych)
Opis zagrożenia: Manipulacja danych treningowych w celu wpływania na zachowanie modelu. Napastnicy wprowadzają złośliwe próbki do zestawu danych treningowych56.

Visual comparison of normal machine learning with a data poisoning attack, showing how corrupted data leads to a compromised model.
Przykład ataku: W systemie wykrywania spamu napastnik może wprowadzić tysiące błędnie oznaczonych wiadomości, powodując, że model zacznie klasyfikować spam jako legalne wiadomości75.
Metody obrony:
- Data Validation: Weryfikacja i walidacja danych treningowych5
- Secure Data Storage: Bezpieczne przechowywanie danych z szyfrowaniem5
- Anomaly Detection: Wykrywanie anomalii w danych treningowych5
- Model Ensembles: Wykorzystanie zespołów modeli trenowanych na różnych podzbiorach danych5
3. ML03:2023 - Model Inversion Attack (Ataki inwersji modelu)
Opis zagrożenia: Napastnicy próbują odtworzyć dane treningowe poprzez analizę odpowiedzi modelu, naruszając prywatność89.
Przykład ataku: Wykorzystując tylko odpowiedzi modelu rozpoznawania twarzy, napastnik może zrekonstruować rozpoznawalne zdjęcia osób z zestawu treningowego, ujawniając wrażliwe dane biometryczne109.
Metody obrony:
- Access Control: Ograniczenie dostępu do modelu i jego predykcji8
- Differential Privacy: Dodawanie szumu do odpowiedzi modelu11
- Model Transparency: Monitorowanie i logowanie wszystkich zapytań8
4. ML04:2023 - Membership Inference Attack (Ataki wnioskowania o członkostwie)
Opis zagrożenia: Określenie, czy konkretny rekord danych był częścią zestawu treningowego modelu, co może naruszać prywatność1213.
Przykład ataku: Napastnik może ustalić, czy dane medyczne konkretnego pacjenta były używane do trenowania modelu diagnostycznego, ujawniając wrażliwe informacje o stanie zdrowia1412.
Metody obrony:
- Model Obfuscation: Zaciemnianie predykcji modelu poprzez dodawanie szumu12
- Regularisation: Techniki regularyzacji L1/L2 zapobiegające przeuczeniu12
- Data Randomization: Losowe mieszanie danych treningowych12
5. ML05:2023 - Model Theft (Kradzież modelu)
Opis zagrożenia: Nieuprawniony dostęp do parametrów modelu w celu skopiowania jego funkcjonalności1516.
Przykład ataku: Konkurencyjne przedsiębiorstwo przeprowadza systematyczne zapytania do API modelu, aby odtworzyć algorytm wart miliony dolarów w kosztach rozwoju1617.
Metody obrony:
- Encryption: Szyfrowanie kodu i parametrów modelu15
- Access Control: Uwierzytelnianie dwuskładnikowe15
- Watermarking: Znakowanie wodne modeli15
- Legal Protection: Ochrona prawna poprzez patenty15
6. ML06:2023 - AI Supply Chain Attacks (Ataki na łańcuch dostaw AI)
Opis zagrożenia: Kompromitacja bibliotek ML, modeli lub narzędzi używanych w systemie, wpływająca na cały łańcuch dostaw1819.
Przykład ataku: Napastnicy tworzą złośliwe repozytoria na platformach jak Hugging Face, podszywając się pod znane organizacje i dystrybuując modele zawierające backdoory1920.
Metody obrony:
- Supply Chain Validation: Weryfikacja pochodzenia bibliotek i modeli20
- Model Scanning: Skanowanie modeli pod kątem złośliwego kodu20
- Secure Development: Bezpieczne środowiska rozwoju20
7. ML07:2023 - Transfer Learning Attack (Ataki transfer learningu)
Opis zagrożenia: Napastnik trenuje model na jednym zadaniu, a następnie fine-tuninguje go na innym, aby spowodować niepożądane zachowanie2122.
Przykład ataku: Model wstępnie wytrenowany na złośliwych danych z twarzami zostaje przeniesiony do systemu rozpoznawania twarzy, powodując nieprawidłowe klasyfikacje i umożliwiając ominięcie zabezpieczeń2221.
Metody obrony:
- Model Isolation: Izolacja środowisk treningowych i wdrożeniowych21
- Secure Datasets: Używanie zaufanych zestawów danych21
- Differential Privacy: Ochrona prywatności w procesie transferu21
8. ML08:2023 - Model Skewing (Przekrzywienie modelu)
Opis zagrożenia: Manipulacja rozkładu danych treningowych poprzez fałszywe dane zwrotne, powodująca systematyczne błędy modelu2324.
Przykład ataku: W systemie kredytowym napastnik systematycznie wysyła fałszywe dane zwrotne, powodując, że model zaczyna faworyzować jego wnioski kredytowe2324.
Metody obrony:
- Feedback Validation: Weryfikacja autentyczności danych zwrotnych23
- Anomaly Detection: Wykrywanie anomalii w danych zwrotnych23
- Access Controls: Kontrola dostępu do systemów zwrotnych23
9. ML09:2023 - Output Integrity Attack (Ataki na integralność wyników)
Opis zagrożenia: Modyfikacja lub manipulacja wyników modelu w celu zmiany jego zachowania lub wyrządzenia szkody systemowi2526.
Przykład ataku: Napastnik uzyskuje dostęp do wyników modelu diagnostycznego w szpitalu i modyfikuje je, powodując błędne diagnozy pacjentów2526.
Metody obrony:
- Cryptographic Methods: Podpisy cyfrowe i secure hash dla weryfikacji wyników25
- Secure Communication: Kanały komunikacyjne SSL/TLS25
- Tamper-evident Logs: Logi zabezpieczone przed manipulacją25
10. ML10:2023 - Model Poisoning (Zatrucie modelu)
Opis zagrożenia: Bezpośrednia manipulacja parametrów modelu w celu zmiany jego zachowania2728.
Przykład ataku: W banku napastnik modyfikuje parametry modelu rozpoznawania znaków na czekach, sprawiając, że cyfra "5" jest rozpoznawana jako "2", prowadząc do nieprawidłowego przetwarzania kwot2728.
Metody obrony:
- Regularisation: Techniki regularyzacji L1/L227
- Robust Model Design: Odporne architektury i funkcje aktywacji27
- Cryptographic Techniques: Zabezpieczenie parametrów modelu27
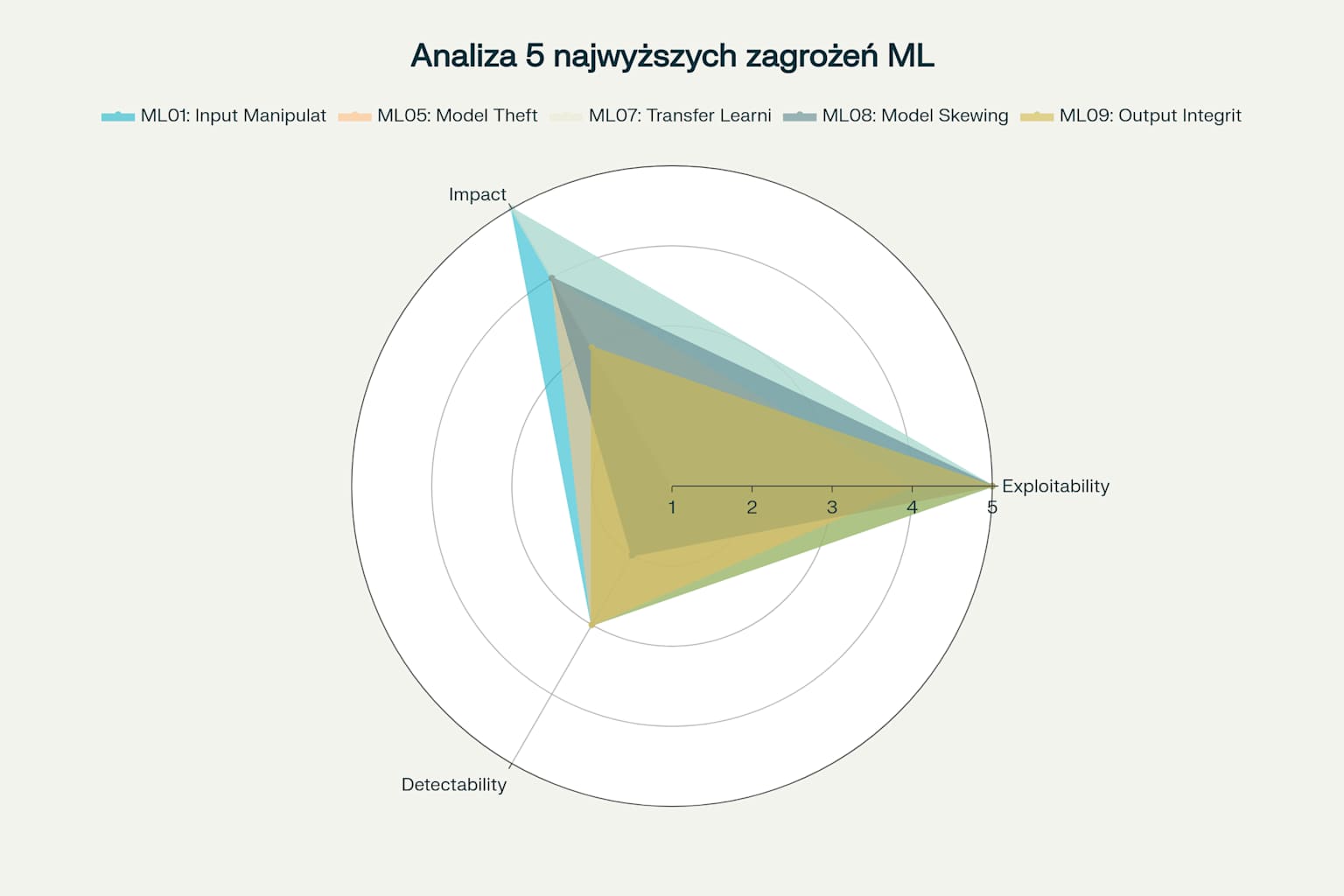
Analiza wielowymiarowa pokazująca profile 5 najwyższych zagrożeń bezpieczeństwa ML w trzech wymiarach: eksploatacja, wpływ i wykrywalność
Strategia kompleksowej obrony
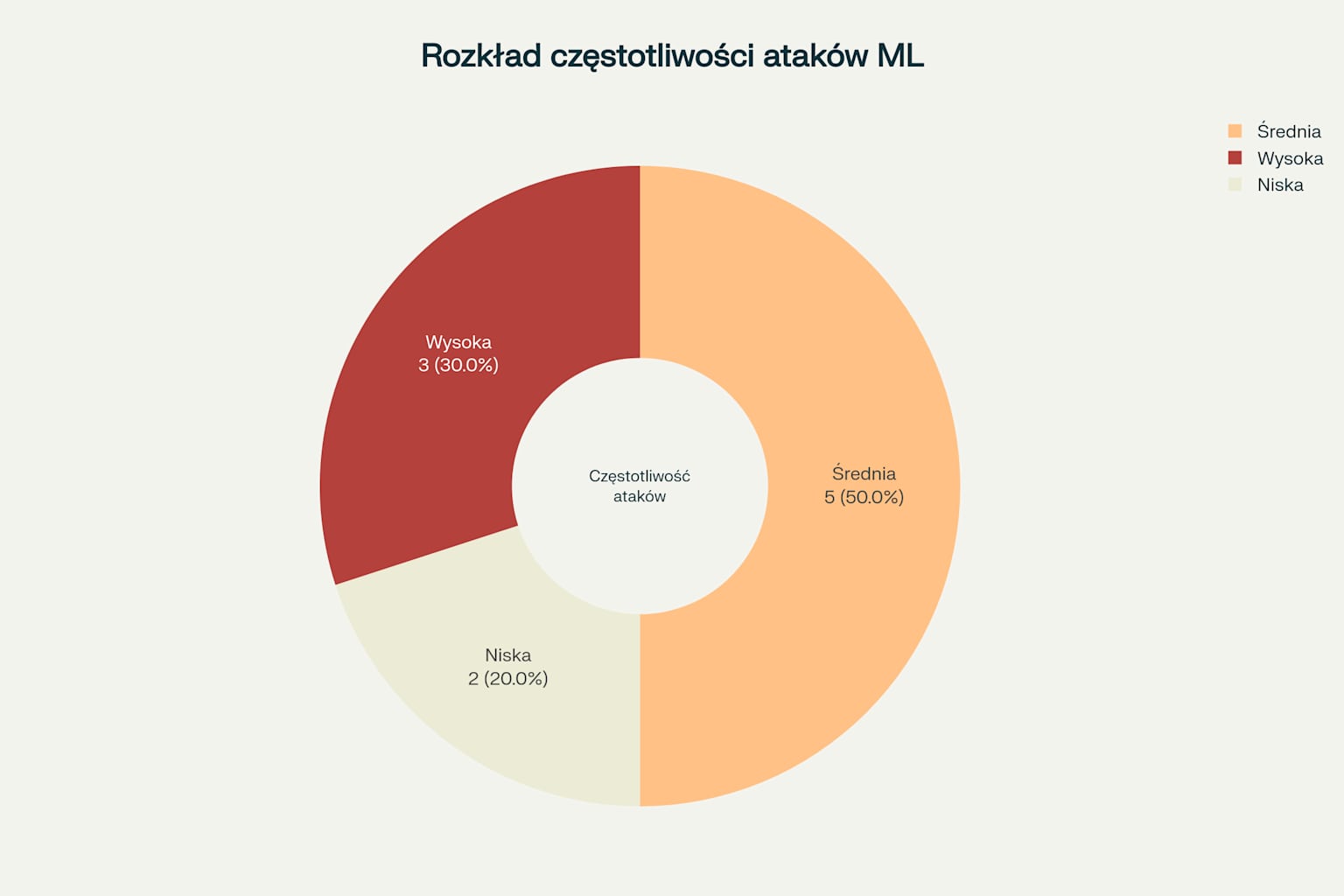
Rozkład częstotliwości ataków na modele ML - pokazuje proporcje zagrożeń o wysokiej, średniej i niskiej częstotliwości występowania
Skuteczna ochrona modeli ML wymaga wielowarstwowego podejścia obejmującego:
Techniczne zabezpieczenia
- Encryption at Rest and in Transit: Szyfrowanie danych i modeli29
- Access Control: Systemy uwierzytelniania i autoryzacji29
- Monitoring: Ciągłe monitorowanie anomalii30
Organizacyjne zabezpieczenia
- Security Culture: Budowanie kultury bezpieczeństwa w zespole31
- Training: Szkolenia dla deweloperów z zakresu bezpieczeństwa ML31
- Incident Response: Plany reagowania na incydenty29
Diagram illustrating a learning-based optical encryption and decryption system for high-security communication.
Najlepsze praktyki implementacji
- Data Quality: Zapewnienie wysokiej jakości i różnorodności danych30
- Model Updates: Regularne aktualizacje modeli i algorytmów30
- Adversarial Testing: Testowanie odporności na ataki adversarialne30
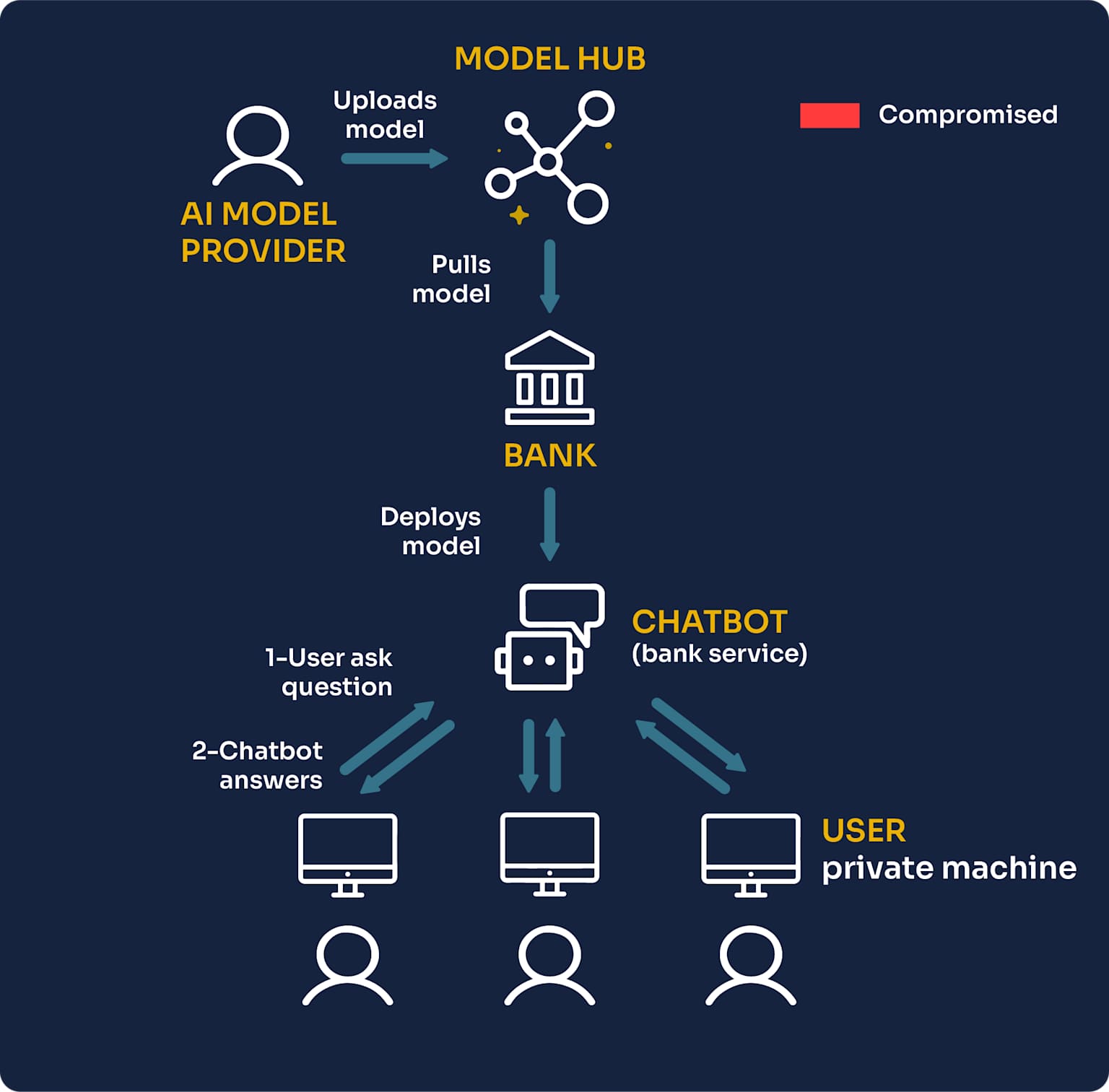
Diagram illustrating the lifecycle and interaction points of an AI model deployed in a banking chatbot service.
Przyszłość bezpieczeństwa ML
Rozwój sztucznej inteligencji przynosi nie tylko nowe możliwości, ale także nowe wyzwania bezpieczeństwa. Organizacje muszą być przygotowane na:
- Evolving Threats: Ciągle ewoluujące techniki ataków32
- Regulatory Compliance: Rosnące wymagania regulacyjne33
- AI-Powered Defense: Wykorzystanie AI do obrony przed AI32
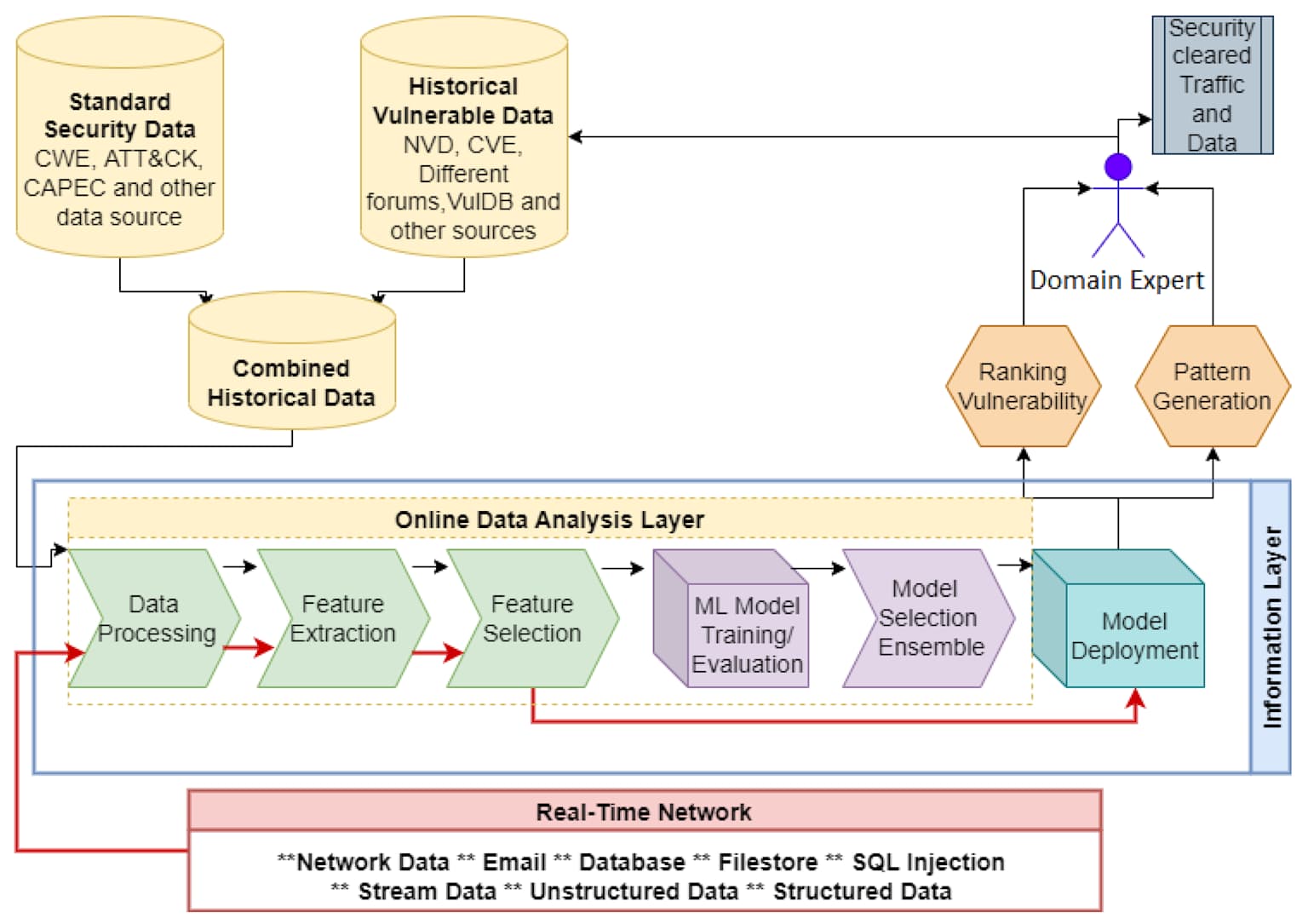
A conceptual diagram outlining a machine learning-driven cybersecurity system for threat detection and mitigation.
Podsumowanie
Bezpieczeństwo modeli uczenia maszynowego nie jest opcjonalne - to krytyczny element sukcesu każdej organizacji wykorzystującej AI. OWASP Machine Learning Security Top 10 dostarcza fundamentalnych wytycznych, które mogą uchronić Twoje systemy przed katastrofalnymi atakami.
Kluczowe wnioski:
- Proaktywność jest kluczowa - zabezpieczenia muszą być wbudowane od początku, nie dodawane post factum
- Wielowarstwowa obrona - żadne pojedyncze zabezpieczenie nie jest wystarczające
- Ciągłe monitorowanie - zagrożenia ewoluują, więc obrona też musi się rozwijać
- Edukacja zespołu - ludzie są pierwszą linią obrony
- Compliance - zgodność z regulacjami staje się coraz ważniejsza
W świecie, gdzie AI staje się fundamentem biznesu, inwestycja w bezpieczeństwo ML to nie koszt, ale konieczność. Organizacje, które zignorują te zagrożenia, mogą zapłacić cenę nie tylko finansową, ale także utratą zaufania klientów i reputacji na rynku.
Pamiętaj: Twój model ML jest tak bezpieczny, jak jego najsłabsze ogniwo. Nie pozwól, aby stało się nim brak odpowiedniej ochrony.